September 9, 2024
Select an option to view the article tailored to your learning style
For those who want to dive deep into the technical details
For those who want to understand the big picture
Few minutes read that gives you the high-level points
LLMs 101: LLMs work by predicting the next word in a sequence, using vast amounts of training data.
Accessing LLMs: These models can be accessed through user interfaces (like ChatGPT), APIs for integration into applications, or self-hosting for full control.
Querying your Excel sheets using LLMs: A practical Oil & Gas use case demonstrating how LLMs can be used to query Excel sheets to extract insights.
Everywhere you turn, you see AI in the headlines and product releases. From "this will take your job" to "the pursuit of AGI", there is a lot of noise, to say the least. It makes it that much more difficult to find tangible use cases, especially in Oil & Gas.
What we hope this newsletter does is shed some light on what "LLMs (AI)" really are and provide a tangible use case you can try for yourself. This will be an ongoing series providing tangible tech examples that can be applied in our industry.
At Petry, we view AI as a powerful tool in our toolkit to help solve the problems we go after. It's at the cornerstone of the Excel copilot we're building.
Artificial Intelligence (AI) refers to the development of models capable of performing tasks that typically require some level of human input. It can be roughly simplified to automated decision-making. The underlying models, math, and methods to make that happen come in many different styles and largely depend on the problem you are trying to solve.
We can associate the relationships between various methods through a nested diagram of categories:
Artificial Intelligence: The outermost category, broadly defined as performing tasks through automated decision-making.
Machine Learning: A subset of AI focused on algorithms that emphasize pattern recognition. For example, an ML model that predicts whether a credit card transaction is fraudulent or not.
Deep Learning: A specialized branch of Machine Learning that utilizes neural networks with multiple layers. Deep Learning is primarily used to learn general patterns in unstructured data, such as images, text, and audio.
Large Language Models (LLMs): LLMs represent the latest advancement in AI, specifically designed for understanding and generating natural language.

Large Language Models (LLMs) are the latest advancement in natural language processing. These models have gained widespread popularity since the release of GPT-3 by OpenAI. The groundbreaking aspect of LLMs is the ability to interact with these models in natural language and get responses similarly.
GPT is an acronym for:
Generative: Refers to the model's ability to generate new text
Pre-Trained: This signifies that the model has been trained on a large amount of text data before being fine-tuned
Transformer: Refers to the underlying architecture of the model
Below is an example where we asked ChatGPT to list restaurants in Houston and organize them in a specific structure. Notice how we were able to ask it for more than one instruction and its ability to parse and understand exactly what needs to be done. These are powerful tools, and this is just scratching the surface of what can be done.

At their core, LLMs are designed to predict the next token (word or subword) in a sequence. Let's use the simplified example below. We can pass on the sentence "Paris is the city" to the model. Once that text is properly analyzed, the model can generate a probability distribution of the most likely word to come next. In this case, it would be the word "of". You can then pass through the extended sentence of "Paris is the city of" to get the next probable word in the sequence and so on.

These models are trained on a vast amount of data to be able to understand how words relate to each other, the structure of sentences, etc. The more recent models from ChatGPT and Gemini have billions of parameters trained on a vast amount of text data from the internet. These models can be extremely expensive to train reaching in the millions.
The training process consists broadly of two phases:
Pre-Training: This is the initial and most resource-intensive stage. The LLM is trained on a vast amount of data with the objective of being able to predict the next word in the sequence. This allows it to build a foundation of general knowledge and language structure. These models are often referred to as "Foundational Models".
Fine-Tuning: At this stage, the foundation model is fine-tuned using a smaller set of data to refine its behavior. An example of this would be to build a specialized model that excels at coding tasks.
The current iteration of LLM models utilizes a transformer architecture that was originally introduced in the paper "Attention Is All You Need" (Vaswani et al., 2017). There are two primary blocks of the architecture: the Encoder and Decoder. We'll step through each at a high level to discuss their purpose, but we'll first need to understand what embeddings are as they play a role in both.
Please note that the actual architecture behind large models is ever-evolving. The true architecture being used in the most popular models remains proprietary. The goal here is to understand the general mechanics of an LLM to provide you context on their inner workings as you use them.

Embeddings are the bridge between human-readable text and numerical representations that these models work with. They are a dense vector representation of tokens in a high-dimensional space. They combine semantic relationships and properties of the text they represent.
Let's refer back to the example above where we asked ChatGPT about restaurants in Houston. We can translate the prompt we provided:
What are the best spots in Houston, TX to eat this weekend? List the top 5 and add an emoji next to each one that represents the restaurant
To the following embedding (shortened for presentation):
[0.009843599, 0.007953431, -0.021098686, 0.018975317, 0.038245205,....]
The importance of converting our input into a vector is for two reasons:
We provide the model with a way to understand the underlying text that has been provided.
We can use this vector to find relationships with other vector data.
Let's take the example of 2 vectors in a high-dimensional space. We can calculate how related they are to one another using a method called cosine similarity. The higher the cosine similarity value is on a scale between 0-1, the more closely related those vector embeddings are.
If they are perfectly identical, the angle between them is 0 and the cosine similarity would equal 1
If they are completely different, the angle between them is 90 degrees and the cosine similarity value equals 0
If they are in opposite directions, the angle between them is 180 degrees, and their cosine similarity is equal to -1
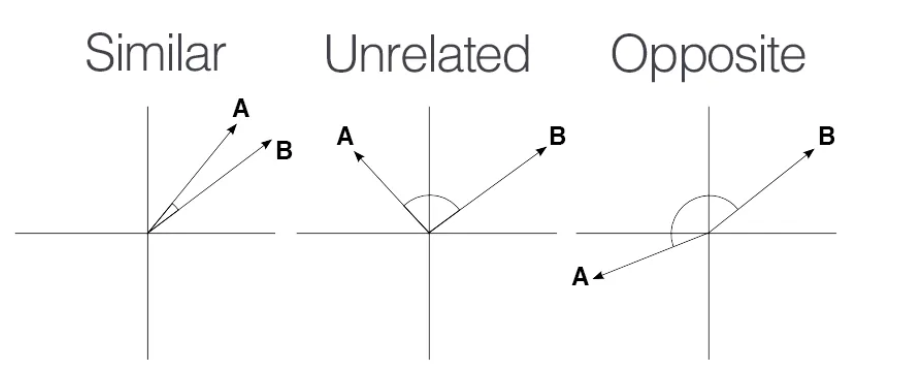
If you expand the example to account for a large number of vectors, each representing some underlying information, we can calculate a similarity score with a prompt that's passed to get some additional information around the text. In a production-scale application, you would save your vector data in a vector database so it can be easier to query.
The encoder's role is to "encode" information about the text that's been passed. It transforms the input into a high-dimensional representation that the model can process. The input embedding is passed through a series of layers that each provide additional contextual information around the text.
These include but are not limited to:
Positional encoding: Provides the model information about the order of the tokens. This is essential as the order of words can drastically change the meaning of a sentence. For example, it allows the model to understand that "The cat sat on the mat" has a different meaning than "The mat sat on the cat."
Contextual encoding: Provides a contextual understanding of each token based on its surrounding tokens. This allows the model to understand nuances in the underlying meaning of the word. For example, it helps differentiate between "bank" as a financial institution and "bank" as the edge of a river.
Self-Attention: This allows the model to weigh the importance of different parts of the input when processing each token. This allows the model to “retain” an understanding of relationships and dependencies within the text.
The result of this encoding process is a high-dimensional matrix that contains important information about the text. It serves as a comprehensive "understanding" of the input text, which is then passed along to the decoder.
The decoder's role is to "decode" the encoder's rich representation back to human-readable text. The decoder consists of a series of layers that determine the most probable next word in the sequence.
The decoding process is iterative and auto-regressive. Once a word is selected, it’s fed back through the decoder becoming part of the input for the next iteration. This continues until a full-text representation is generated and reaches a stopping point.
The inference process, generating results from a trained model, can be summarized as follows:
Input Embedding: Converting the prompt provided into a vector embedding
Encoding: Encodes the input with additional context that will be helpful for the decoder
Decoding: The output of the encoder is converted back into human-readable text by selecting the most probable word in the sequence until an end state is reached.
User Interface (UI): You can interact with LLMs through apps or tools that have a user interface. Almost every major foundational model has a dedicated site for you to interact with them. You can check out https://chatgpt.com/ to test OpenAIs latest model.
API: For developers, there are APIs available that let you integrate LLMs directly into your own applications.
Self-Hosted Model: If you like to have full control, you can host an LLM yourself on your own infrastructure. This way, you manage the data and run the model on your own servers.
Excel is the workspace of the Energy industry. It's fast, flexible, and has a low barrier to entry. Often, Engineers and Analysts are juggling any number of sheets and have inherited previous work as well. Each Excel sheet can be thought of as a slice of context into the overall picture of the business. Whether that's insights into well analysis, documentation of workovers, or budget for the quarter, they contain critical insights.
We can leverage the power of LLMs to query these Excel sheets to retrieve some of those insights. We'll build out a simplified example of how we can use LLMs to query an Excel sheet.
Github: The full code for this example can be found in our open-source repo:
Interactive Demo: You can try an interactive demo of the solution for free on our site with your own Excel sheets here
We'll be using OpenAI's ChatGPT model in Python. Please refer to the README.md file in the repo to get the example set up locally with all the required dependencies.
In order to interact with OpenAI's client, we'll first need to import their library to instantiate a client using your API key.
from openai import OpenAI
""" Initialize the OpenAI client"""
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY")) We'll then load our Excel document using pandas into a data frame. We'll keep things simple in this first article and not worry about processing the data in the Excel sheet.
import pandas as pd """Read the excel sheet into a pandas df""" df = pd.read_excel(file_path)
The OpenAI client expects an array of messages. The structure of each message can be broken down as follows:
message = { 'role': 'system' or 'user, 'content': 'some-string'}Role: The role defines the "who" in terms of the message content
System: This represents the LLM itself. We often define a system message before any messages from the user. This defines the "character" and rules the LLM should use when responding to a user prompt.
User: This demonstrates the message came from the user
Content: A string that contains the data we want to pass to the LLM
For this specific task, let's define an initial system prompt to the LLM to clarify its objective. Take note of the first line clearly defining its objective and the bulleted rules that it should follow in its reasoning. This helps guide the LLM in its process.
""" Setup the system content for the LLM. You can think of this as defining its role/character """ system_content = """ You are a helpful assistant that answers questions about Excel data that the user provides. Rules: -Do not provide any information that is not present in the Excel data. -Do not make any assumptions about the data.Do not provide any information that is not explicitly asked for. -Do not provide any information that is not directly supported by the data. -Do not use any profanity or offensive language. """
Next, let's create a user prompt template. This will be the second message in the messages array.
"""
Convert the DataFrame to a string so we can include it in the prompt
"""
df_string = df.to_string()
""" Create the user prompt for the LLM. We provide the LLM with the Excel data and the question to answer"""
initial_user_prompt = f"""
Given the following Excel data: {df_string}
Here is the question I would like answered: {question} based on the data provided.
Please provide the answer in a text format.
""" There are two key things we did above:
We provide the LLM context of our Excel sheet by converting the DataFrame that stores it into a string. This provides the necessary context for the LLM to gain access to your data as it evaluates the user's prompts. In a production example, you would most likely query a vector database that contains vector embeddings of your document(s) to augment the user's prompt.
We added some clarifying instructions that the user may not necessarily provide when interacting with the LLM. We insert the question from the user directly in the {question} space.
Now we'll combine the content into an array called chat and provide it directly to our OpenAI client. We'll use the gpt-3.5-turbo model for our use cases as it's powerful enough to get the level of answers we need. In much more complex use cases, you could change the model to use more advanced models like GPT-4.
chat = [{"role": "system", "content": system_content},
{"role": "user", "content": initial_user_prompt}]
"""Query the LLM with the prompt"""
response = client.chat.completions.create(model="gpt-3.5-turbo", messages=chat)
answer = response.choices[0].message.content.strip() We then parse out the answer from the client's response. We specifically specified that the answer should be sent back as text. We could have instructed the LLM to output the result in a specific JSON object structure if needed, which can be very useful in specific use cases.
In a production-grade app, we would continue to append the array with the LLM response as system and the user questions to create a full conversation to keep passing to the model. That provides it the chat history and context the LLM needs to continue to provide relevant and meaningful answers.
Click here to test out an interactive demo of what we just built. Simply drop in the Excel sheet you'd like to query and chat directly with the LLM. Here is an example chat using the example-data.xlsx file in the GitHub repo.
